自编码器(Autoencoder)
自编码器是一种非监督学习机器学习模型。
自编码器的目标是学习一个函数 ,使其能够将输入数据 映射到另一个维度 的空间中。而如果 ,则称为压缩自编码器(Undercomplete Autoencoder);如果 ,则称为扩展自编码器(Overcomplete Autoencoder)。在这一节将关注压缩自编码器。
非监督学习
非监督学习是在说数据集将仅仅包含数据点而不包含其所对应的标签。即
其中 是一个数据点。而机器学习模型的目标是学习这个数据集实现任务。
模型结构
自编码器被定义为两部分:编码器(Encoder) 和解码器(Decoder) 。编码器将输入空间 映射到一个隐藏空间 ,而解码器将隐藏层 映射到输出数据 。即
其中 是编码器, 是编码器的参数; 是解码器, 是解码器的参数。
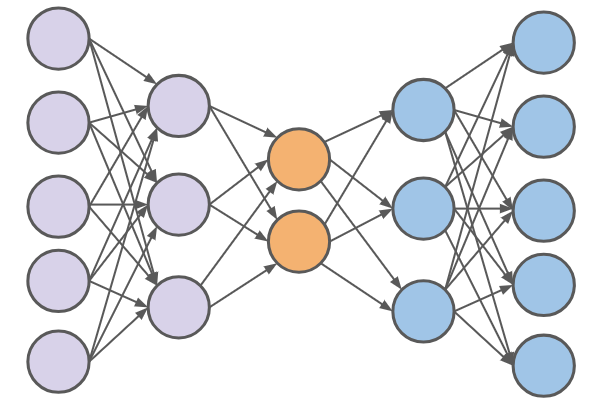
上图是一个简单的自编码器结构。紫色部分是编码器,蓝色部分是解码器。编码器将输入数据通过计算,最终得到隐藏层(橙色)的表示。而解码器将隐藏层的表示映射到输出数据。
损失函数
损失函数揭示了为什么自编码器是怎么进行无监督训练。自编码器的目标是最小化重构误差(Reconstruction Error)。
如果我们把整个模型看作映射 ,则这个函数可以被记为:
如果我们将编码层认为在压缩(从高维数据映射到低维数据),那么我们可以认为解码器是一个解压的过程,或者说在重建原始数据。如果我们的模型的重建数据 和原始数据 相似,那么我们可以认为模型是学习到了数据的特征,即我们期望 。
因此我们可以定义距离函数为:
因此可以使用均值平方差(MSE)定义损失函数:
而我们的目标是最小化这个损失函数。因此可以用梯度下降法来优化这个损失函数。即
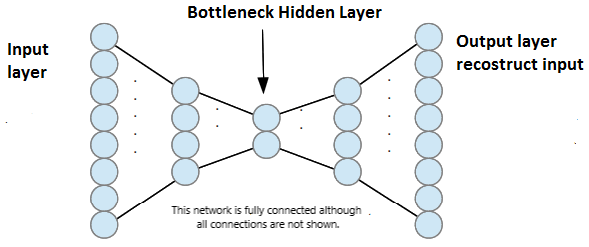
BottleNeck 层
全局最优的情况是模型可以完美重建整个数据,即 。因此模型学到的单位函数(identity function)。
这种情况会发生在隐藏层的维度 大于等于输入层的维度 。因为这样模型可以学到一个单位函数,即 、。而这样的模型是没有意义的。其没有学到数据的特征,而只是记住所有的数据点。
 [https://discourse.opengenus.org/t/understand-autoencoders-by-implementing-in-tensorflow/3668]
[https://discourse.opengenus.org/t/understand-autoencoders-by-implementing-in-tensorflow/3668]
这时候,我们需要引入一个 BottleNeck 层,即隐藏层的维度 小于输入层的维度 。模型在经过这个 BottleNeck 层时,由于维度降低,会丢失一些信息,这样模型就不可能学到单位函数。因此就能够学到数据的特征。
用数学标记,则为:
学习完后
当模型学习完后,我们可以使用编码器 来提取数据的特征。
但是由于自编码器是一个无监督学习模型,因此我们无法直接使用自编码器来进行其他任务(我们并不清楚隐藏层的特征是什么)。我们以二元分类任务为例,我们可以使用自编码器的隐藏层特征作为输入,然后训练一个监督学习的分类模型,例如 SVM 或逻辑回归,这个模型被定义为 。
需要注意的是自编码器并不适合进行生成数据。如果我们需要生成数据,我们通常需要从特征空间(或隐空间)中采样一些数据,并将数据放进解码器以生成。
而自编码器的隐藏层是一个固定的特征提取器,对于整个隐空间 (特征空间),其特征都是一个个点,而这些点相对于这个空间太过稀疏(Sparse),难以直接通过采样来生成数据。为了生成数据,我们可以使用变分自编码器或生成对抗网络。