
这一节内容非常复杂。需要你有足够的耐心和一定的数学功底。第一遍阅读可以略读或跳过这一节。
支持向量机(Support Vector Machine, SVM)是一种二分类模型,其基本模型是定义在特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化。SVM 通过间隔最大化,可以使得模型对噪声更加鲁棒,从而提高模型的泛化能力。
和逻辑回归一样,支持向量机是一个二分类模型,且其也是个线性模型,即其分割超平面为 wTx+b=0。我们可以将数据集分为两类,一类为正类,一类为负类。
线性可分是指存在一个(超)平面可以将数据集完全分割开,即正类在(超)平面的一侧,负类在(超)平面的另一侧。
在下面我们将首先讨论线性可分情况下的支持向量机。再介绍线性不可分的情况。
我们考虑分类算法,我们只是关注是否所有的数据点被正确分类了,而并不在乎我们到底选择了哪一个(超)平面用于用于分隔数据点。但是支持向量机不仅仅关注分类是否正确,还关注分类的边界。我们希望分类的边界尽可能远离数据点,这样可以使得模型对噪声更加鲁棒,从而提高模型的泛化能力。
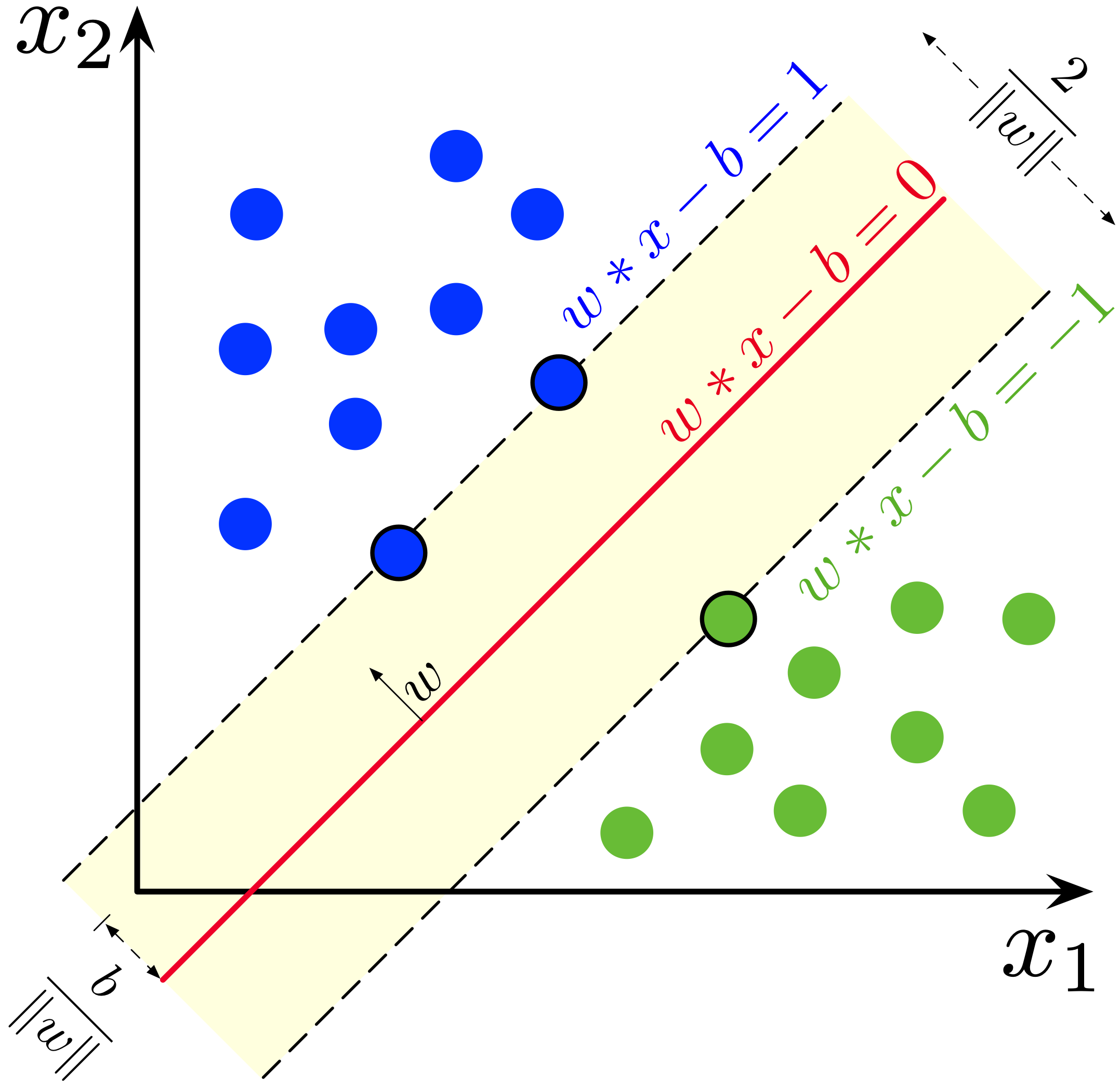
[https://en.m.wikipedia.org/wiki/File:SVM_margin.png]
上图是 SVM 的示例图。红色线是我们的假说。蓝色点为正类,绿色点为负类。黄色区域则是由离假说最近的正类和负类点组成的间隔(Margin)。间隔线(虚线)与假说平行,而在间隔线上的数据点,我们称其为支持向量(Support Vector)。我们希望寻找一个假说可以将两个类被正确分开,且能够使这个间隔最大化。
而因此,我们定义了新的假说:
h(x)={+1−1 if wTx+b>0 if wTx+b<0
即,如果这个点在超平面的上侧,我们将其分类为正类,否则分类为负类。
在一切开始前,我需要先介绍一下点到(超)平面(后简称平面)的距离。
我们定义平面 H 为 wTx+b=0。
并定义点 Q (q1,q2,q3,...,qN) 到平面 H 的距禽为 dist(Q,H)。
我们想要知道怎么计算点 Q 到平面 H 的距离。
取平面任意一点 P (p1,p2,p3,...,pN),且因为平面上的点满足 wTx+b=0,因此有 wTp+b=0。
向量 PQ=q−p,其相对于平面法向量的投影为 ∣PQ∣cosθ,其中 θ 为 PQ 和 w 的夹角。考虑其投影的几何性质,我们可以得到 dist(Q,H)=∣PQ∣cosθ。
令法向量 n⊥H:(w1,w2,...,wn),有
PQ⋅n∣PQ∣cosθ=∣PQ∣∣n∣cosθ=∣n∣n⋅PQ
因此则有:
dist(Q,H)∵∴dist(Q,H)=∣n∣n⋅PQ=∣∣w∣∣w⋅(q−p)=∣∣w∣∣1⋅(wTq−wTp)=∣∣w∣∣1⋅(wTq+b−(wTp+b))wTp+b=0=∣∣w∣∣1⋅(wTq+b)=∣∣w∣∣wTq+b
根据上一节,我们可以定义距离公式:
dist(h,xi)=∣∣w∣∣∣h(xi)∣
我们定义距离
di=dist(h,xi)=∣∣w∣∣∣h(xi)∣
考虑 y∈{−1,+1},因此由:
yi=⎩⎨⎧+1−1+1−1 if wTxi+b>0分类正确 if wTxi+b<0分类正确 if wTxi+b≤0分类错误 if wTxi+b≥0分类错误
即如果分类正确,yi(wTxi+b)>0,如果分类错误,yi(wTxi+b)≤0。考虑 yi∈{+1,−1},即乘上它只会改变 wTxi+b 的正负号而不会改变其绝对值,因此如果所有点都被正确分类,我们可以把边距改写为
di=∣∣w∣∣∣h(xi)∣dis.t.∀=∣∣w∣∣yi(wTxi+b)⇓=∣∣w∣∣yi(wTxi+b)(xi,yi)∈D.yih(xi)>0
经过此变换,我们可以得到一个更加简洁的表达式:
s.t.di=∣∣w∣∣yi(wTxi+b)∀(xi,yi)∈D.yih(xi)>0
我们的目标是最大化最小的间隔,即我们要先找到最小的间隔 γn=minndn,然后寻找使其最大的参数 w 和 b。因此我们可以定义原问题为:
wheres.t.w,bargmax{nmindn}dn=∣∣w∣∣yn(wTxn+b)∀(xi,yi)∈D.yih(xi)>0
即
s.t.w,bargmax{nmin∣∣w∣∣yn(wTxn+b)}∀(xi,yi)∈D.yih(xi)>0
由于在求最小点的时候,我们固定了 w ,因此我们可以把 w 提出来,即
s.t.w,bargmax{∣∣w∣∣1nminyn(wTxi+b)}∀(xi,yi)∈D.yih(xi)>0
考虑如果存在 w 和 b 能满足超平面。则超平面可以被定义为
wTx+b=0
如果我们对 w 和 b 进行缩放,即 w⇒kw,b⇒kb,这样我们可以得到
(kw)Tx+kbk(wTx+b)=0=0
如果我们考虑最小边距的点,即 minnyn(wTxn+b),考虑总是存在常量 k 使得minnyn(kwTxn+kb)=1,因此我们可以对平面进行乘 k变换,因此有 minnyn(wTxn+b)=1。而由于最小化的边距被定义为了 1,因此约束条件被改写为
s.t.∀(xi,yi)∈D.yih(xi)≥1
因此我们可以改写原问题为
s.t.w,bargmax{∣∣w∣∣1}∀(xi,yi)∈D.yih(xi)≥1
边界 γ 被定义为
γ=∣∣w∣∣1
而最大化一个数的倒数等价于最小化这个数的倒数的倒数,即
s.t.w,bargmin{∣∣w∣∣}∀(xi,yi)∈D.yih(xi)≥1
考虑我们最小化一个绝对值,也就在最小化这个绝对值的平方,因此有:
s.t.w,bargmin{∣∣w∣∣2}∀(xi,yi)∈D.yih(xi)≥1
为了方便之后的求导,我们可以把最小化的平方乘上一个正系数 21,即:
s.t.w,bargmin{21∣∣w∣∣2}∀(xi,yi)∈D.yih(xi)>0
我们对 x 进行非线性变换,即 x⇒ϕ(x),这样我们可以得到
s.t.w,bargmin{21∣∣w∣∣2}∀(xi,yi)∈D.yi(wTϕ(xi)+b)≥1
我们需要优化这个函数
考虑原问题
s.t.w,bargmin{21∣∣w∣∣2}∀(xi,yi)∈D.yi(wTϕ(xi)+b)≥1
由于约束比较复杂,我们难以直接优化。因此我们需要改写原问题以方便优化。
我们可以定义一个惩罚函数 g(w,b),当违反约束时,这个惩罚会很大,而当满足约束时,这个惩罚会很小。因此在优化这个整体问题时,我们也在优化惩罚函数,即尽可能符合约束。即我们可以定义把原问题重新写为:
w,bargmin{21∣∣w∣∣2+g(w,b)}
如果我们能将约束转化为上述的 g 函数,则我们就可以把原问题转化为一个无约束问题。因此我们需要构建惩罚函数 g。
我们首先改写约束条件:
yi(wTϕ(xi)+b)yi(wTϕ(xi)+b)−11−yi(wTϕ(xi)+b)≥1⇓≥0⇓≤0
我们可以定义惩罚函数为
s.t.g(w,b)=i=1∑Nαi(1−yi(wTϕ(xi)+b))αi≥0
在这里,我们称 αi 为拉格朗日乘子。(因为这个方法本质上被称为拉格朗日乘子法)且其:
- 当 xi 不是支持向量,即 αi=0,这个点对于最终的分类没有影响
- 当 xi 是支持向量,即 αi>0,这个点对于最终的分类有影响
当 αi>0 时,我们称 xi 为支持向量。需要注意的是尽管有可能 xi 在边界上,但是其 αi 仍然可能为 0。
我们希望使得所有违反约束的点的惩罚尽可能大,即我们希望最大化这些惩罚,因此我们可以改写惩罚函数为:
s.t.g(w,b)=maxi=1∑Nαi(1−yi(wTϕ(xi)+b))αi≥0
我们将惩罚函数带入原问题,我们可以得到:
s.t.w,bargmin{21∣∣w∣∣2+αmaxn=1∑Nαn(1−yn(wTϕ(xn)+b))}yn(wTϕ(xn)+b)≥1αn≥0
由于内侧优化 maxα 并不会影响到 21∣∣w∣∣2,因此可以提出来,即:
s.t.w,bminαmax{21∣∣w∣∣2+n=1∑Nαn(1−yn(wTϕ(xn)+b))}yn(wTϕ(xn)+b)≥1αn≥0
根据一些数学推导,我们可以得到最终的优化问题为:
s.t.αmaxw,bmin{21∣∣w∣∣2+n=1∑Nαn(1−yn(wTϕ(xn)+b))}yn(wTϕ(xn)+b)≥1αn≥0
我们将省略上侧这一步的推导,简单来说我们可以将优化看成两部分:
- 最小化 21∣∣w∣∣2
- 最大化 ∑n=1Nαn(1−yn(wTϕ(xn)+b))
前者可以被轻易证明是凸的(convex),因此其的极小值为全局最小值。
而后者也可以被证明为凹的(concave)。因此其的极大值为全局最大值。
由 Minimax 定理,在此情况下的 maxmin 是可以进行交换优化的。
对于固定的 y,有 f(⋅,y):X→R 是 concave,且
对于固定的 x,有 f(x,⋅):Y→R 是 convex。
则我们有
x∈Xmaxy∈Yminf(x,y)=y∈Yminx∈Xmaxf(x,y)
具体请参考 Minimax Theorem - Wikipedia
即:
s.t.αmaxw,bminL(α,w,b)={21∣∣w∣∣2+n=1∑Nαn(1−yn(wTϕ(xn)+b))}yn(wTϕ(xn)+b)≥1αn≥0
我们对其进行求导,即
∂w∂L∂b∂L=w−n=1∑Nαnynϕ(xn)=−n=1∑Nαnyn
如果损失最小,我们可以得到:
∂w∂L=0∂b∂L=0⇒⇒w=∑n=1Nαnynϕ(xn)∑n=1Nαnyn=0
将 w 和 b 代入 L,我们可以把优化问题改写为
s.t.αargmaxL(α)=n=1∑Nαn−21n=1∑Nm=1∑Nαnαmynymϕ(xn)Tϕ(xm)αn≥0n=1∑Nanyn=0
定义核函数 κ(xn,xm)=ϕ(xn)Tϕ(xm),可以把优化问题改写为
s.t.whereαargmaxL(α)=n=1∑Nαn−21n=1∑Nm=1∑Nαnαmynymκ(xn,xm)αn≥0n=1∑Nanyn=0κ(xn,xm)=ϕ(xn)Tϕ(xm)
原问题的预测是很直觉的,即:
predictprime(x)=sign(h(x))=sign(wTϕ(x)+b)=sign(n=1∑Nαnynκ(xn,x)+b)
其中 sign 为符号函数,即如果输入为正数,则输出为 +1,否则输出为 −1。
而对偶问题的预测有所不同。由于我们有 w=∑n=1Nαnynϕ(xn),我们将其带入 h(x),我们可以得到:
h(x)=wTϕ(x)+b=(n=1∑Nαnynϕ(xn))Tϕ(x)+b=n=1∑Nαnynϕ(xn)Tϕ(x)+b=n=1∑Nαnynκ(xn,x)+b
predictdual(x)=sign(h(x))=sign(n=1∑Nαnynκ(xn,x)+b)
但是如果遇到非线性可分情况,我们需要引入软间隔(Soft Margin)。我们可以引入一个松弛变量 ξn,其可以使得一些点可以在越过边界的情况下被正确分类。我们可以定义新的约束条件:
∀n∈{1,2,...,N}.yn(wTϕ(xn)+b)≥1−ξnξn≥0
即
∀n∈[1,N].yn(wTϕ(xn)+b)+ξn≥1(ξn≥0)
而其实我们本质期望这个松弛变量 ξn 越小越好,因此我们可以定义惩罚函数 gξ 为:
gξ=Cn=1∑Nξn
其中 C 为一个超参数(hyperparameter),其可以控制惩罚的大小。我们可以把原问题改写为:
s.t.w,b,ξargmin{21∣∣w∣∣2+Cn=1∑Nξn}∀n∈[1,N].yn(wTϕ(xn)+b)+ξn≥1ξn≥0
超参数是在开始学习过程之前设置的参数,其控制或影响学习的过程。在学习过程中,超参数是固定的,不会被学习和改变。超参数的选择是非常重要的,不同的超参数会导致不同的学习效果。
我们可以将问题逐步改写为对偶问题以方便求解:
s.t.w,b,ξargmin{21∣∣w∣∣2+Cn=1∑Nξn}∀n∈[1,N].1−ξn−yn(wTϕ(xn)+b)≤0−ξn≤0
改写为拉格朗日乘子法为:
Lwhere=21∣∣w∣∣2+Cn=1∑Nξn−n=1∑Nβnξn+n=1∑Nαn[1−ξn−yn(wTϕ(xn)+b)]αn≥0βn≥0
和线性可分情况类似(即没有软间隔的情况,也被称为硬间隔),我们的优化问题因此被转化为:
whereαmaxw,bminLαn≥0βn≥0yn(wTxn)≥1+ξnwherew,bminαmaxLαn≥0βn≥0yn(wTxn)≥1+ξn
上述两个问题是等价的(Minimax Theorem)。
而如果我们对此拉格朗日乘子法取最低点,即为
∂w∂L=0∂ξn∂L=0∂b∂L=0⇒⇒⇒w−∑n=1Nαnynϕ(xn)=0C−βn−αn=0−∑n=1Nαnyn=0⇒⇒⇒w=∑n=1Nαnynϕ(xn)αn+βn=C∑n=1Nαnyn=0
其中 αn+βn=C 可以改写为 αn=C−βn,考虑 βn≥0
因此则有 αn∈[0,C]。我们称这一条限制为 Box Constraint。
L∵∴∵∴=21∣∣w∣∣2+Cn=1∑Nξn−n=1∑Nβnξn+n=1∑Nαn[1−ξn−yn(wTϕ(xn)+b)]=21∣∣w∣∣2+Cn=1∑Nξn−n=1∑Nβnξn−n=1∑Nαnξn+n=1∑Nαn[1−yn(wTϕ(xn)+b)]=21∣∣w∣∣2+Cn=1∑Nξn−n=1∑N(αn+βn)ξn+n=1∑Nαn[1−yn(wTϕ(xn)+b)]αn+βn=C=21∣∣w∣∣2+Cn=1∑Nξn−n=1∑NCξn+n=1∑Nαn[1−yn(wTϕ(xn)+b)]=21∣∣w∣∣2+n=1∑Nαn[1−yn(wTϕ(xn)+b)]=21∣∣w∣∣2+n=1∑Nαn[1−yn(wTϕ(xn))−ynb]=21∣∣w∣∣2+n=1∑Nαn[1−yn(wTϕ(xn))]−n=1∑Nαnynb=21∣∣w∣∣2+n=1∑Nαn[1−yn(wTϕ(xn))]−bn=1∑Nαnynn=1∑Nαnyn=0=21∣∣w∣∣2+n=1∑Nαn[1−yn(wTϕ(xn))]=21∣∣w∣∣2+n=1∑Nαn−n=1∑NαnynwTϕ(xn)
因此这个公式可以被拆成三部分:
- 21∣∣w∣∣2
- ∑n=1Nαn
- −∑n=1NαnynwTϕ(xn)
我们对第一项进行修改
∵∴21∣∣w∣∣2=21wTww=n=1∑Nαnynϕ(xn)21∣∣w∣∣2=21(i=1∑Nαiyiϕ(xi))T(j=1∑Nαjyjϕ(xj))
21∣∣w∣∣2=21(i=1∑Nαiyiϕ(xi))T(j=1∑Nαjyjϕ(xj))=21i=1∑Nj=1∑Nαiαjyiyjϕ(xi)Tϕ(xj)=21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)
我们对第三项进行修改
−n=1∑NαnynwTϕ(xn)=−n=1∑Nαnyn(j=1∑Nαjyjϕ(xj))Tϕ(xn)=−i=1∑Nαiyi(j=1∑Nαjyjϕ(xj))Tϕ(xi)=−i=1∑Nαiyi(j=1∑Nαjyjϕ(xj)Tϕ(xi))=−i=1∑Nαiyi(j=1∑Nαjyjκ(xj,xi))=−i=1∑Nj=1∑Nαiyiαjyjκ(xj,xi)=−i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)
将改写好的量带入:
L=21∣∣w∣∣2+n=1∑Nαn−n=1∑NαnynwTϕ(xn)=21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)+n=1∑Nαn−i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)=n=1∑Nαn−21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)
而我们的目标为最大化 L,即
s.t.αmaxL(α)0≤αi≤Ci=1∑Nαiyi=0
更完整地
s.t.αmaxn=1∑Nαn−21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)αi∈[0,C]i=1∑Nαiyi=0
即我们可以定义优化问题为:
s.t.αmin21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)−n=1∑Nαnαi∈[0,C]i=1∑Nαiyi=0
而目标函数为:
J=21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)−n=1∑Nαn
通过上述过程,我们获得了我们需要优化的问题:
s.t.αmin21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)−n=1∑Nαnαi∈[0,C]i=1∑Nαiyi=0
相比于传统的直接使用梯度下降,SVM使用一个名为 SMO 算法。上述问题我们定义其为二次编程(QP)问题。SMO 是一个启发式算法,其将这个问题分解成很多子 QP 问题再逐个解决分析。其性能比直接梯度下降好很多。
我们的目标是通过选择 α 从而使这个问题最优化。
这个算法的核心想法是每一步,从 α 中选择两个 αi、αj 并让其他 α 固定,然后调整这两个参数。通过反复循环这个操作,完成整体优化。
即:
初始化 α
循环:
选择一对αi、αj
保持其他 α固定,优化 αi 和 αj
考虑是如果我们抽取一个 αk,而其仍需要满足约束 ∑i=1Nαiyi=0,因此则有:
αkyk+i∈[0,N],i=k∑αiyiαkykαk=0=−i∈[0,N],i=k∑αiyi=−yk1i∈[0,N],i=k∑αiyi
而考虑 yk={−1,1}=yk1,因此有
αk=−yk1i∈[0,N],i=k∑αiyi=−yki∈[0,N],i=k∑αiyi
而对于这种情况,调整 αk 是难以完成。
因此我们最少选择两个参数。
选择 α :最简单的做法是选择 αi,αj=0 ,我们将在后面讨论具体应该怎么做
优化 α :
由于我们固定了 αi,αi 以外的所有参数,因此有
n=1∑Nαnynαiyi+αjyj+n∈[1,N];n=i,j∑αnynαiyi+αjyj=0=0=−n∈[1,N];n=i,j∑αnyn
如果令 ζ=−∑n∈[1,N];n=i,jαnyn,则有:
αiyi+αjyj=ζ
需要注意 $\zeta$ (zeta)和 $\xi$ (xi)并不是一个字母。
$\xi$ 表示松弛变量
$\zeta$ 表示一个常量
我们如果在更新 αj ,我们可以计算其下界 L:
这里我们将拆分两种情况:yi=yj 和 yi=yj
情况 yi=yj,我们有 αi+αj=ζ 或者 −αi−αj=ζ
αi+αj=ζ⇒αj=ζ−αi∵∴∴αi∈[0,C]αj=ζ−αiC≥0αj∈[ζ−C,ζ]αj∈[αi+αj−C,αi+αj]
αi+αj=−ζ⇒αj=−ζ−αi∵∴∴αi∈[0,C]αj=−ζ−αiC≥0αj∈[−ζ−C,−ζ]αj∈[αi+αj−C,αi+αj]
因此此情况下界 L=max(0,αi+αj−C) ,上界 H=min(C,αi+αj)
情况 yi=yj,我们有 αi−αj=ζ 或者 −αi+αj=ζ
αi−αj=ζ⇒αj=αi−ζ∵∴∴αi∈[0,C]αj=αi−ζC≥0αj∈[−ζ,C−ζ]αj∈[αj−αi,C+αj−αj]
−αi+αj=ζ⇒αj=αi+ζ∵∴∴αi∈[0,C]αj=αi+ζC≥0αj∈[ζ,C+ζ]αj∈[αj−αi,C+αj−αj]
因此此情况下界 L=max(0,αj−αi) ,上界 H=min(C,C+αj−αi)
我们可以改写 αi 使用 αj 表示:
αiyi+αjyjαiyiαi=ζ=ζ−αjyj=yiζ−αjyj
我们对目标函数相对于特定 αk 进行求导(这里使用 αk 是为了避免和目标函数中的 αi 重合):
∂αk∂J=∂αk∂21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)−n=1∑Nαn=i=1∑Nαiyiykκ(xi,xk)−1=0
i=1∑Nαiyiykκ(xi,xk)−1i=1∑Nαiyiykκ(xi,xk)αkyk2κ(xk,xk)+i=k∑αiyiykκ(xi,xk)αkκ(xk,xk)αk=0=1=1=1−i=k∑αiyiykκ(xi,xk)=κ(xk,xk)1−∑i=kαiyiykκ(xi,xk)