过拟合和欠拟合
过拟合(overfit)和欠拟合(underfit)是两个机器学习中很常见的词汇,其通常代表着模型的两种状态
- 过拟合(overfit):过度优化,导致模型只是记住数据集中的信息,而不能作用到数据集外的任务。
- 欠拟合(underfit):过少优化,模型还没有到最优点便停止了优化。
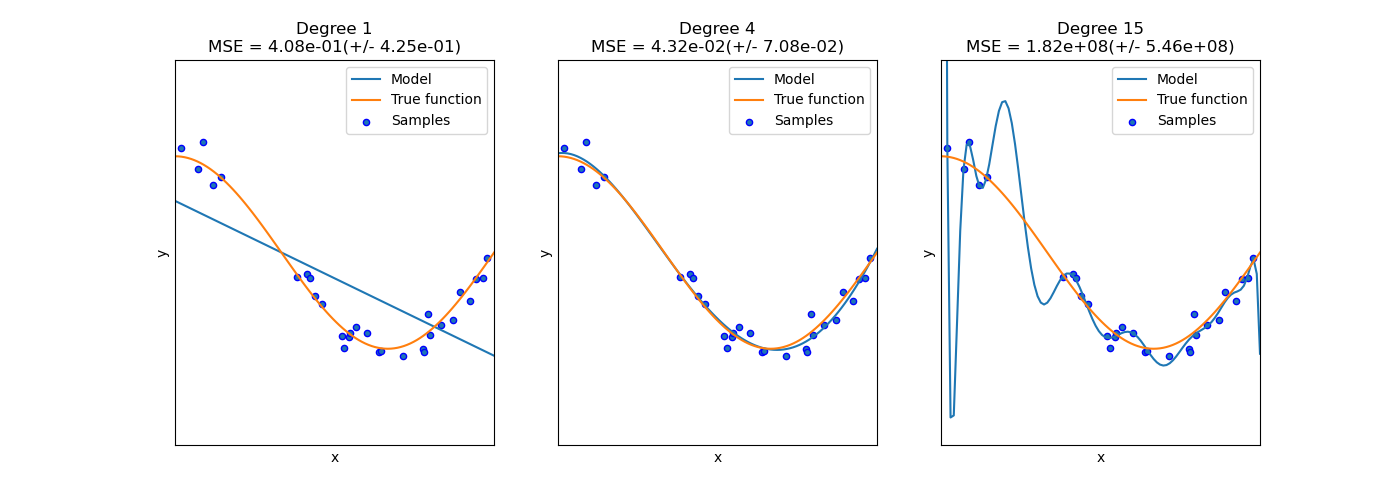 [https://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html]
[https://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html]
上图分别是欠拟合、正常拟合和过拟合。
过拟合 Overfitting
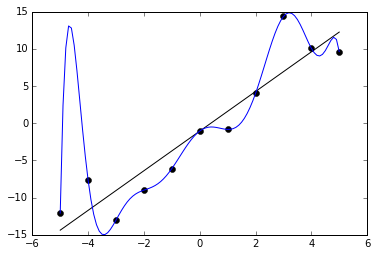
[https://en.wikipedia.org/wiki/Overfitting#/media/File:Overfitted_Data.png]
上图是一张过拟合的可视化图。图中 11 个点被蓝色的模型完美拟合,因此从训练角度其损失为 0,因此是个”完美的“的模型。但是如果考虑实际情况,黑色线的模型反而可能可以获得更高的性能。
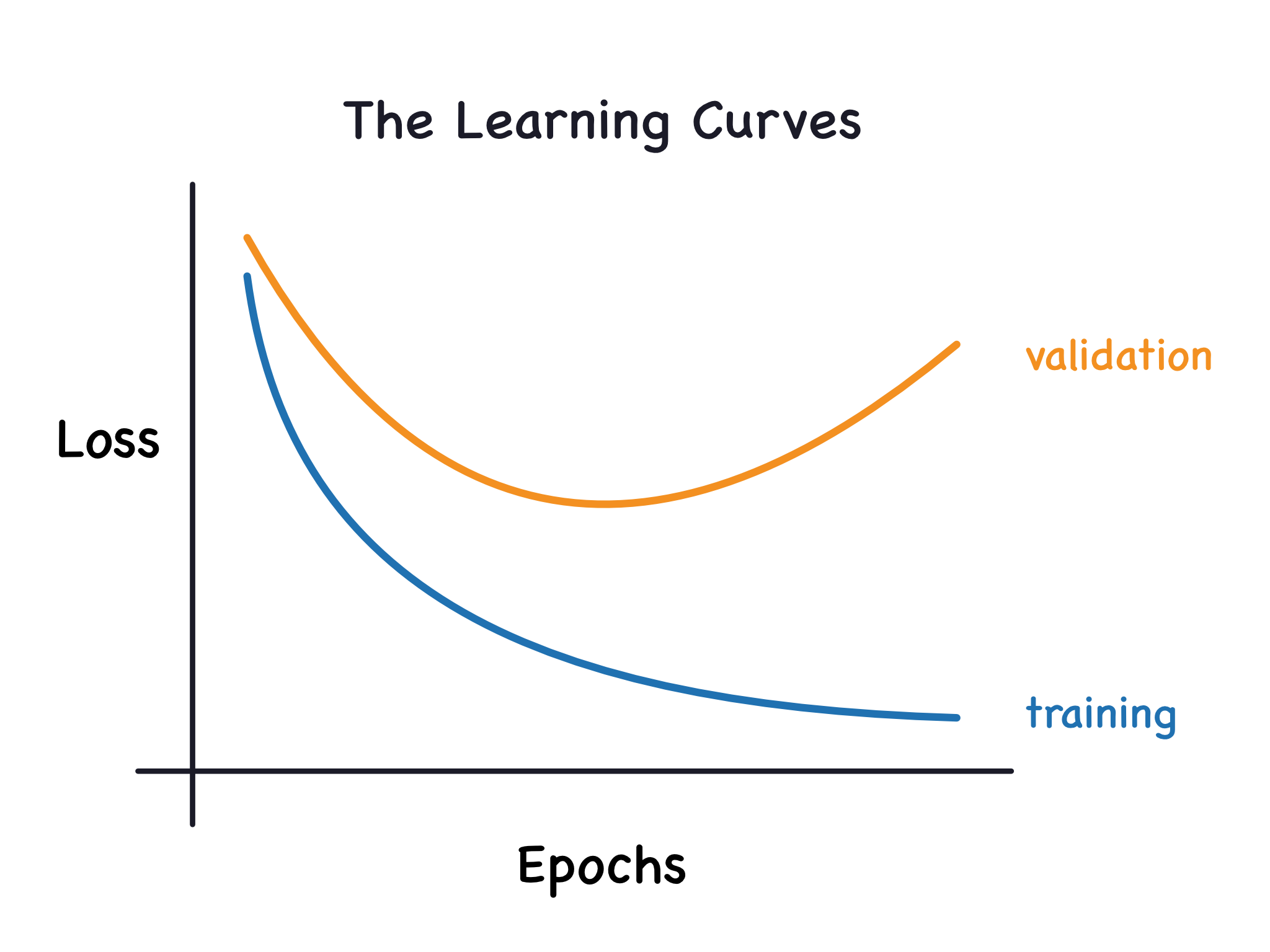
[https://www.kaggle.com/code/ryanholbrook/overfitting-and-underfitting]
上图是训练不同迭代次数与验证损失和训练损失的关系。过拟合发生在训练损失仍在降低,但是验证损失却在上升。即模型正在记住所有训练集的点,但是不能再在正确预测未见过的数据(即无法泛化)。
过拟合发生并不是单个因素导致的,而是由很多因素混合导致的:
- 模型太复杂:模型越复杂,则其能完美拟合更多的情况。也因此其更可能完美拟合数据集。而过度复杂的模型可能会导致过拟合。
- 噪声:噪声是不可避免的,其出现在物理世界,因此也很难一直接消失。
- 模型和目标函数复杂度不一样:这也可以归结于模型太复杂的情况。
为了避免过拟合,我们通常可以使用如下几种技巧:
- 标准化(Standardisation)
- 正则化(Regularisation)
- 提早停止(Early Stop)
正则化(Regularisation) 是指在优化的损失函数增加一个正则项 ,并通过最小化目标函数以最小化这个正则项。
这个正则项通常是一个与权重复杂度有关的函数。通过最小化正则项以降低权重复杂度。
常用的正则项有 和
我们会发现如果权重越复杂,其正则项越大,因此我们可以通过最小化正则项以降低权重复杂度。当然,我们会暂时跳过讨论 和 的区别。
提早停止(Early Stop) 是指当优化发生过拟合时候,提早停止,并使用最优的模型。
我们期望模型可以对未见过的数据能正常的预测,因此我们会在验证损失最低的情况下,停止训练,而不是等到训练损失最低的情况再停止训练。
欠拟合 Underfitting
欠拟合通常发生在
-
训练还没有达到最优就停止,即训练损失和泛化损失都在降低,但是训练停止了。
-
模型太弱了,没法正确拟合。
解决方案就很简单了:多练练(x)或者换个更强模型