线性回归
什么是线性回归
线性回归(Linear Regression)是一个机器学习模型用于完成回归任务。为解释线性回归,我们将其分为两个部分:线性和回归。
[https://simple.wikipedia.org/wiki/Linear_regression#/media/File:Linear_regression.svg]
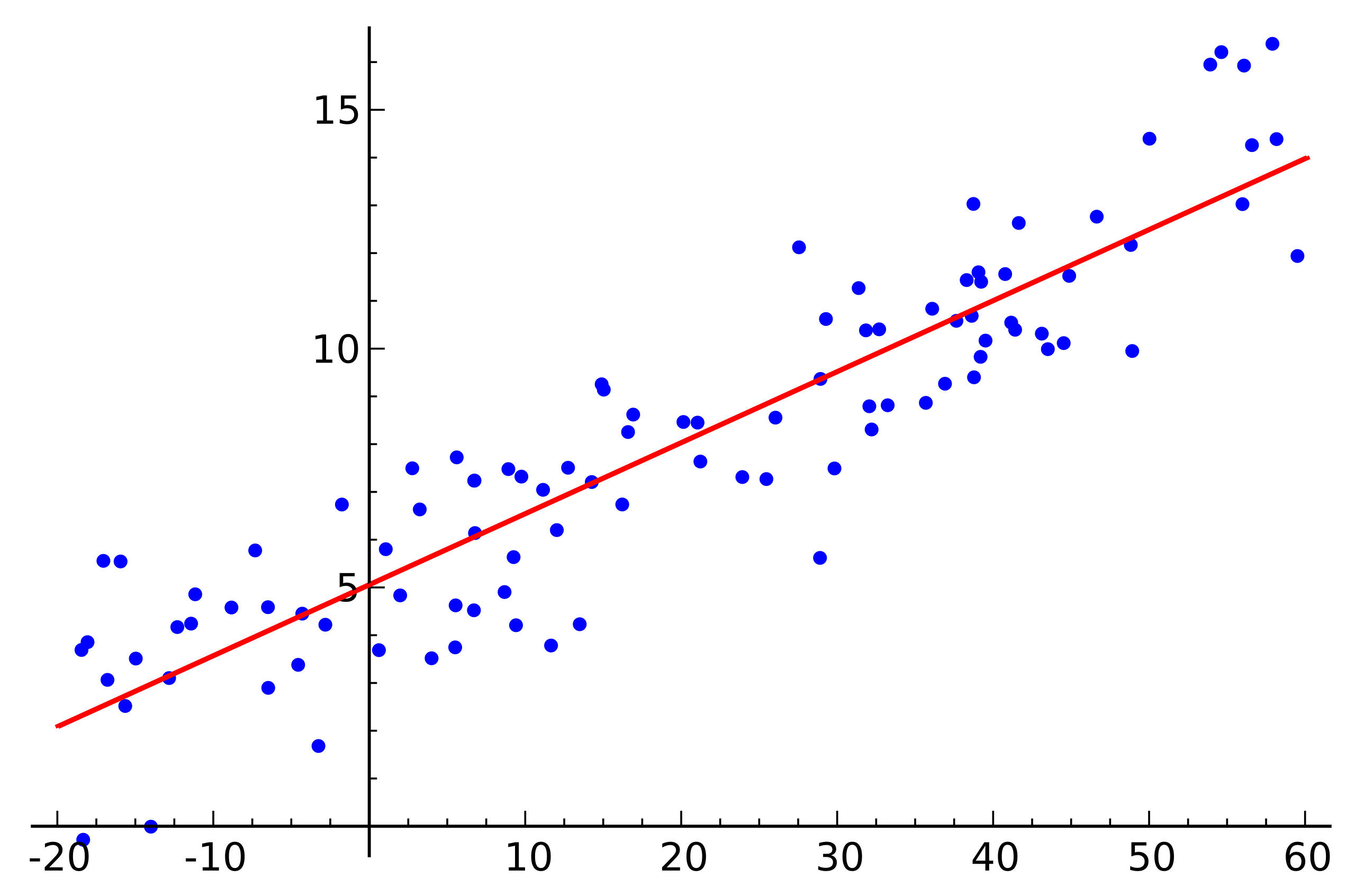
上图是线性回归的一个演示图。我们可以看到有很多点,和一根线。这根线就是我们的线性回归模型。我们称之为其是我们的假说。而这些点就是我们的数据集。我们的目标是找到一根线,使得这根线可以最好的拟合这些点(或者说,更好地服从数据点的趋势)。而用线去拟合这些点,我们就称之为回归。
而线性(Linear)则是指这个模型是一个线性函数(Linear function),其可以被定义为:
用一维的例子解释,我们可以简易的认为对于输入的每一个特征 ,我们都会有一个权重 ,而我们的线性函数就是将所有的特征乘上对应的权重后相加,再加上一个偏置 。而这个线性函数就是我们的线性回归模型。
即考虑一维线性函数 ,我们可以将其改写为 ,其中 , 是偏置。而对于多维的情况,我们可以将其改写为 。
如果我们假设 ,并令 则我们可以认为
其中 是一个 维的向量, 是一个 维的向量, 是 的第 个元素, 是 的第 个元素。而 是我们的线性函数,其可以将输入 映射到一个标量值。
表示转置(Transpose)运算。这里的 可以理解为向量 和向量 的点乘,即
阅读 向量和矩阵 节了解更多关于向量的知识。
更严格的定义
向量我们可以认为一个有 个数字的数组,而标量则是一个单独的数字。
我们需要从数据集尝试寻找参数使线性函数能够最好的拟合。我们可以定义数据集为:
即数据集是由 个数据点组成,每个数据点包含一个输入 和一个输出 。而我们的目标是找到一个权重 ,使得我们的线性函数 能够最好的拟合数据集 。
用数学语言来描述,我们假设输入数据是一个 维向量 ,而输出数据是一个标量 。我们可以定义输入空间 为一个 维的实数空间,而输出空间 为一个实数空间。即:
而我们的线性函数 可以被定义为是从输入空间 到输出空间 的一个映射,即:
成本函数
那我们应该如何去寻找到最终最佳的呢?我们需要定义一个函数,叫损失函数。其用于衡量我们的预测值 与真实值 之间的差距。如果我们能通过某些手段最小化这个损失函数,我们也就相当于让模型可以学习到最佳的。这个过程就是我们所说的训练过程。
而线性回归模型的损失应该怎么定义呢?相信聪明的朋友已经知道了!我们可以通过计算预测值与真实值之间的差距来定义损失函数。我们可以考虑 与模型预测的 的距离,即 。
如果我们的模型预测的值与真实值之间的距离越小,那么我们的模型就越好。因此我们可以定义距离函数为这两个点的几何距离,即欧式距离:
其中我们将其转化为平方的形式,是因为平方相比于绝对值更容易求导,而且在求导的时候也不会受到绝对值的影响。
而上述式在最后进行平方根运算,而我们在求导的时候会遇到开方的问题,这会使得我们的求导变得复杂。因此我们可以将其转化为平方的形式,是因为平方相比于开方更容易求导,而且在求导的时候也不会受到开方的影响。而其与几何距离函数有着相同的单调性,这也意味着我们可以通过最小化平方距离 来最小化几何距离。
因此我们可以定义距离函数为:
而考虑上式只考虑了一个样本,而我们的数据集中有多个样本,因此我们需要对所有的样本求平均值以得到平均损失。因此我们可以定义损失函数 为:
因此目前我们尝试寻找一个权重 ,使其最小化成本函数 为了方便后面的数学操作,我们可以将整个函数除以2,这样在后续求导的时候可以消去2,方便计算。而考虑乘上是一个正的常数,不会影响其的单调性与求导,也不会影响最小化这个式子的权重,因此我们可以将目标函数改写为
优化目标函数
在完成问题的定义后,我们的目标转化成了最小化成本函数。在高中数学中,我们可以知道:一个函数的极值点只存在于导数为 0 的点。因此如果我们想获得一个参数使损失函数最小化,我们可以对成本函数求其求导数(更严谨来说,是对于成本函数的参数求偏导)。
在高中我们学习了导数,而偏导数是导数的一种推广。在高中我们学习的导数是函数的变化率。这个函数其实有一个隐式条件,即其只有一个自变量(通常为 )。
而如果面对有多个自变量的函数(被称为多变量函数),我们需要使用偏导数。偏导数是在将其他的自变量视作常数时,对其中一个自变量求导。我们可以将其理解为在多维空间中的导数。
其运算规则与导数相同,只是在求导的时候,我们需要将其他的自变量视作常数。
可以阅读 从导数到偏导 节了解更多关于向量的知识。
易知该损失函数的极值点是全局最低点,故严格证明暂时略去。
简单来说,对于一个凸函数(convex function),其的全局最小值会出现在其导数为 0 的情况(需要注意的是,凸函数可能会有多个点使其导数为 0,且这些点的函数值均为全局最小值)。而我们的成本函数可以被证明为凸函数,因此我们可以通过对其求导数来获得全局最小值。我们会在后续章节讨论凸函数的性质。
求其极值点。令其偏导值为 0:
通过上述操作,我们可以获得最佳的(星号 表示最佳),这个过程就是我们所说的训练过程。我们可以通过这个过程来训练我们的模型,使得模型可以学习到最佳的,从而可以对未知的数据进行预测。
由于我们可以通过代数直接获得函数的解析解,我们也称其为封闭解(Closed-form solution)。
需要注意的是并不是所有的问题都拥有封闭解,有些问题可能会有多个解,有些问题可能会有无穷个解,有些问题可能会没有解。而应对这种情况,我们会选择使用迭代的方法来求解(我们又称其为优化(Optimisation))。在后续的章节中,我们会介绍如何使用迭代的方法来求解线性回归问题。
矩阵形式
当然,为了方便实际运用,我们可以将整个过程用矩阵形式表达。
我们定义:
因此有:
其中 是原来的损失函数。
因此有:
对其求导:
令导数为 0,我们可以得到:
即:
这就是我们的线性回归矩阵形式的解析解。